Introduction
The NFL Scouting Combine is a week-long showcase occurring every February at Lucas Oil Stadium in Indianapolis. College football players perform physical and mental tests in front of National Football League coaches, general managers, and scouts from all 32 NFL teams for an intense, four-day job interview in advance of the NFL Draft. Here is a brief breakdown of the measurable drills:
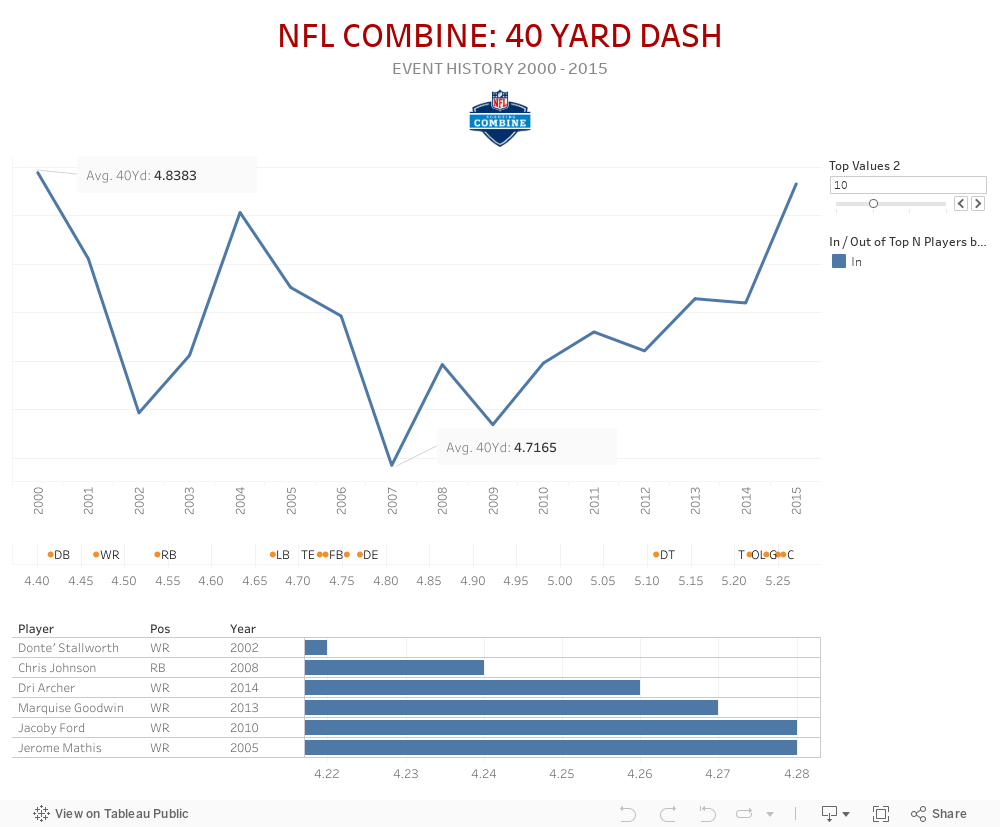
40-Yard Dash
The 40-yard dash is the marquee event at the combine. It's kind of like the 100-meters at the Olympics: It's all about speed, explosion and watching skilled athletes run great times. The scouts are looking for an explosion from a static start.
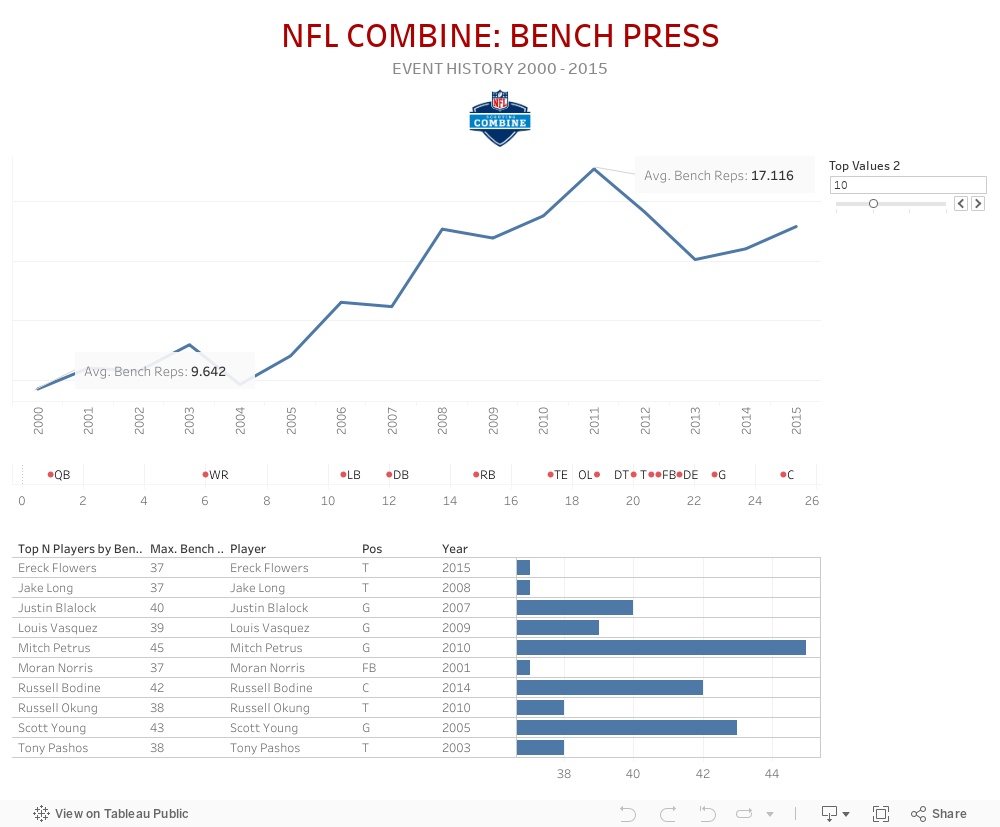
Bench Press
The bench press is a test of strength -- 225 pounds, as many reps as the athlete can get. What the NFL scouts are also looking for is endurance. Anybody can do a max one time, but what the bench press tells the pro scouts is how often the athlete frequented his college weight room for the last 3-5 years.
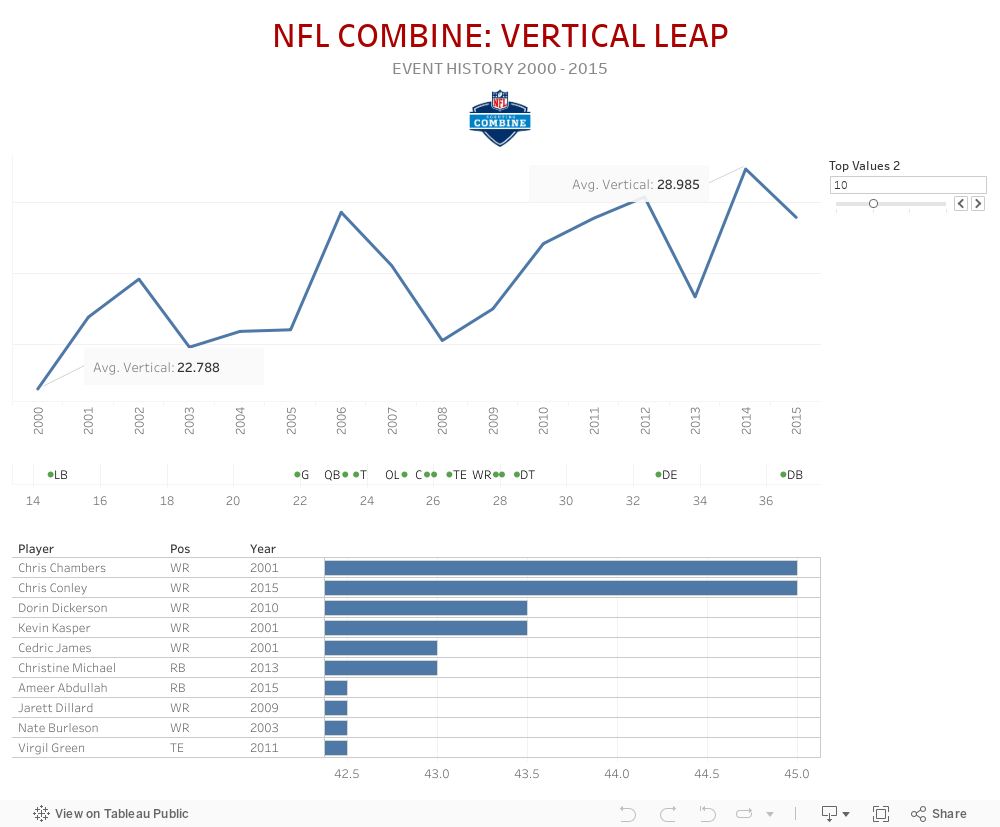
Vertical Jump
The vertical jump is all about lower-body explosion and power. The athlete stands flat-footed and they measure his reach. It is important to accurately measure the reach, because the differential between the reach and the flag the athlete touches is his vertical jump measurement.



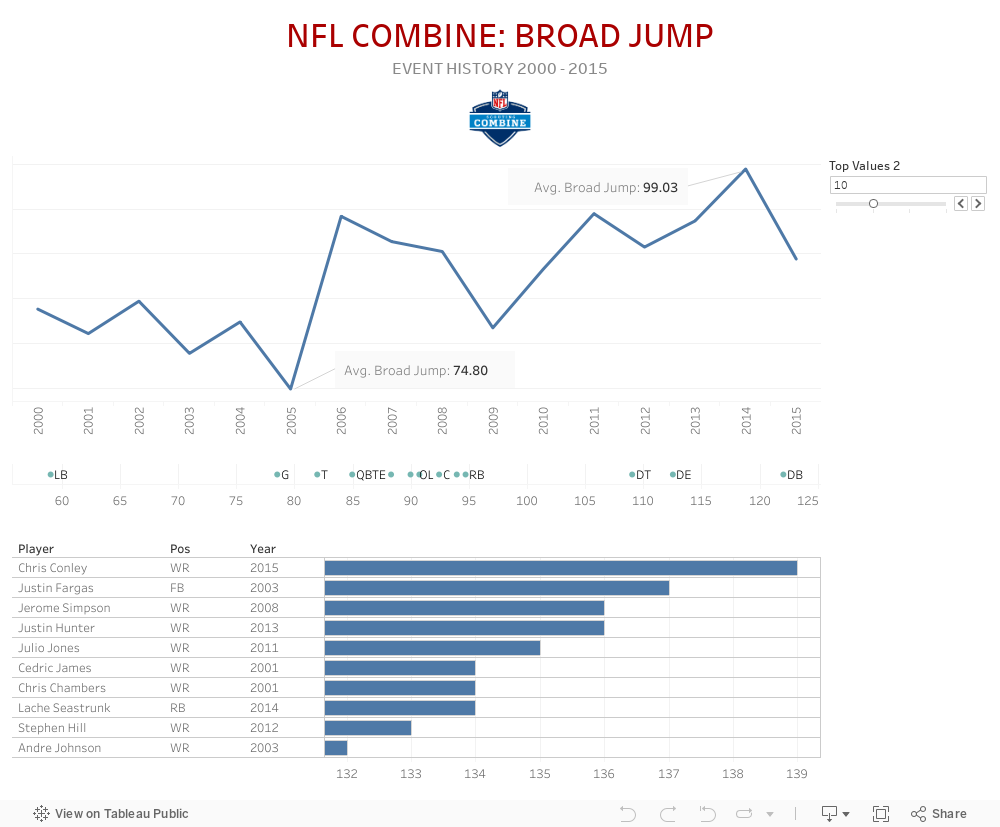
Broad Jump
The broad jump is like being in gym class back in junior high school. Basically, it is testing an athlete's lower-body explosion and lower-body strength. The athlete starts out with a stance balanced and then he explodes out as far as he can. It tests explosion and balance, because he has to land without moving.
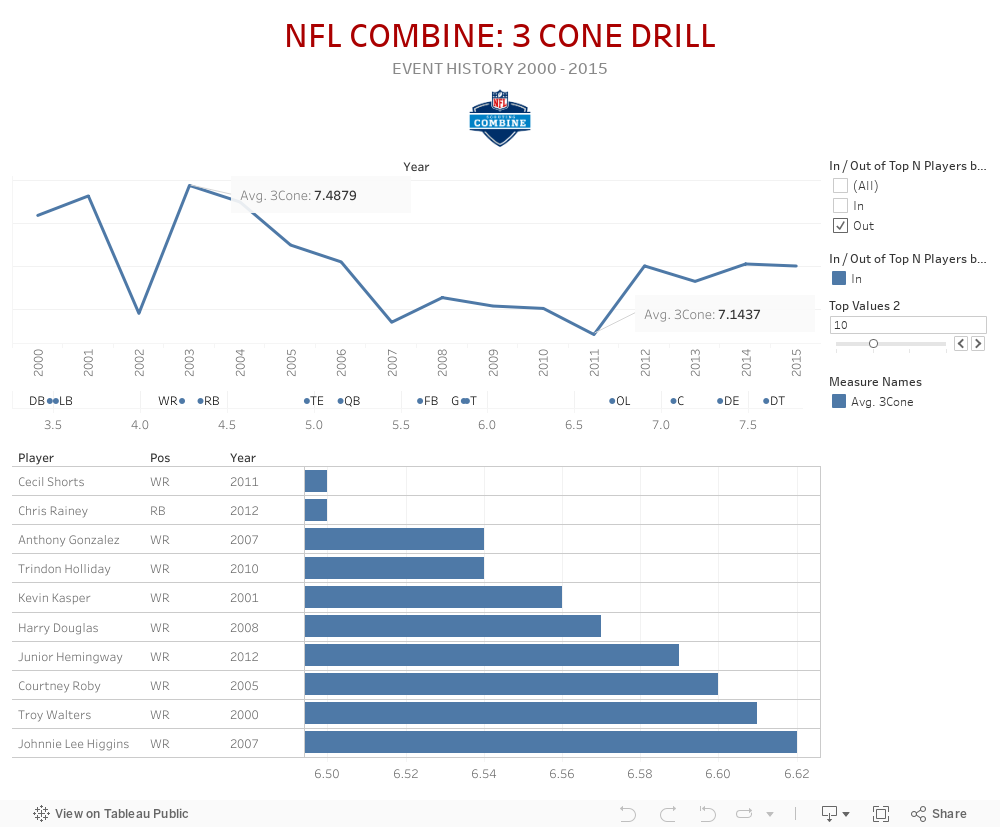
3 Cone Drill
The 3 cone drill tests an athlete's ability to change directions at a high speed. Three cones in an L-shape. He starts from the starting line, goes 5 yards to the first cone and back. Then, he turns, runs around the second cone, runs a weave around the third cone, which is the high point of the L, changes directions, comes back around that second cone and finishes.
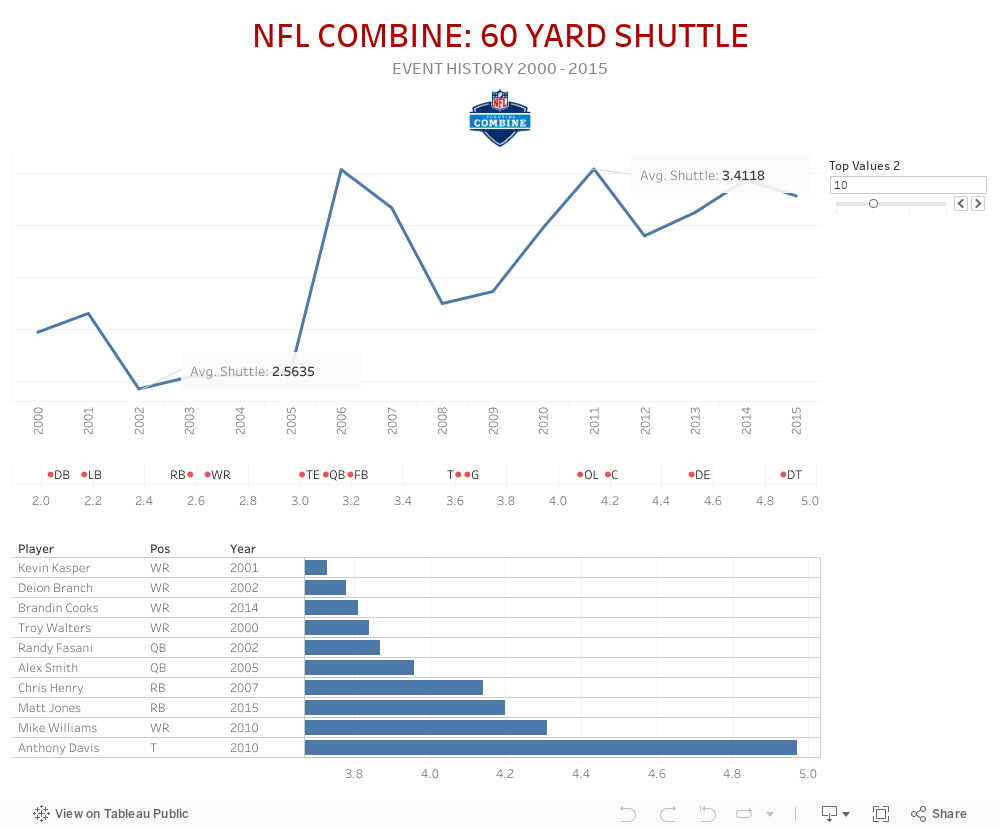
Shuttle Run
The short shuttle is the first of the cone drills. It is known as the 5-10-5. What it tests is the athlete's lateral quickness and explosion in short areas. The athlete starts in the three-point stance, explodes out 5 yards to his right, touches the line, goes back 10 yards to his left, left hand touches the line, pivot, and he turns 5 more yards and finishes.



For our group's project, we are going to analyze and explore data based on the NFL's yearly draft combine. Our goal, through machine learning, is to run tests to determine any correlation between a player’s score in each of the tested categories, and then their subsequent draft position. Our first step is to clean the data from each single year, then determine any correlations and/or conclusions in our data, and display our findings through an HTML page. After analyzing the data, we hope to determine the following:
The Data
College & NFL Stats
In addition to the Combine data, we collected detailed College and NFL stats from 1985 to 2015 from actual game play. Across the 31 years of data gathered, there are over 8400 lines of data. The data includes 23 points of measure which include some of the following:
The Combine
With increasing interest in the NFL Draft, the scouting combine has grown in scope and significance, allowing personnel directors to evaluate upcoming prospects in a standardized setting. The Combine tests players in the 40 yard dash, vertical jump, bench press, broad jump, shuttle, and three cone drill. Teams use this data to try and assess how well a player’s athletic traits can translate into NFL production. The data set we have acquired is from Kaggle, and includes all offensive and defensive players who have participated in the NFL's yearly combine, from the years 2000 through 2017. Each year has on average 300 participants, with information such as position played and drafted position. These players all have recorded specific individual scores in different tested areas such as a speed, agility and strength.
Combine Data & Outcome
The first application of machine learning was intended to determine if any model could predict, with some degree of accuracy, that an athlete would get drafted, regardless of the round. Utilizing the Combine data only, several models used scaled input data sets to determine a binary outcome of “drafted” or “undrafted”. The summary box-plot chart provides a high-level view of the accuracy of each model based on a 10-fold cross validation procedure.

As you can see, three models: Logistical Regression (LR), Linear Discriminant Analysis (LDA), and Support Vector Classifier (SVM) seem to provide the highest accuracy with lower standard deviations between tests. K Nearest Neighbors (KNN), Random Tree Classifier (RFC), Decision Tree Classifier (CART), and Gaussian NB (NB) do not produce the level of accuracy or consistency between tests as the aforementioned three models. Further outputs from the algorithms produced relative importance of each Combine athletic test on the output. For the most part, there was not a single input of the eight total that was significantly weighted heavier than the rest. The “40 Yard Dash” carried the most importance with a value of 0.167 and the player’s “Height” had the least impact on the outcome with a weight of 0.076.

In addition to the tests listed above, a neural network algorithm and a deep learning algorithm were applied to improve accuracy. Both algorithms leveraged 100 epochs and the deep learning method used 2 additional layers to see if a more predictive model could be obtained. The neural network produced results consistent with the previous models (68.3%) but not gaining any significant improvements in accuracy. The deep neural network actually performed worse compared to other models with a value of 65.7%.

In addition to the tests listed above, a neural network algorithm and a deep learning algorithm were applied to improve accuracy. Both algorithms leveraged 100 epochs and the deep learning method used 2 additional layers to see if a more predictive model could be obtained. The neural network produced results consistent with the previous models (68.3%) but not gaining any significant improvements in accuracy. The deep neural network actually performed worse compared to other models with a value of 65.7%.

Quarterback Analysis & Draft Outcome
In an attempt to improve the accuracy of the model, additional player data was added to the original dataset. A Player’s historic performance during their NCAA Football careers should have an impact on NFL teams’ decision during the draft. The additional eight data points highlights their performance on a per game basis. Due to the size and scope of the data, the following analysis only focused the Quarterback position. The same algorithms were applied as in the previous analysis to determine if the additional data impacted accuracy. Surprisingly, there outcome showed little improvement and the models produced a much higher variation in outputs between tests, as shown in the box plot. Logistical Regression and Linear Discriminant Analysis remained the top models but Support Vector Classifier dropped in accuracy joining the other models.

The weights of the inputs remained relatively equally distributed over the 16 inputs as in the previous analysis, as well. This would suggest that the model contains too many inputs and efforts should be made to eliminate those that have little effect on the outcome.

Contrary to the previous model outputs, the Neural Network saw an improvement in accuracy with the additional inputs, rising slightly to 71.4%. The Deep Learning algorithm did indicate any improvement in accuracy.

Round Outcome
The next progression in the analysis was to use machine learning to predict the actual round the player was drafted. We used logistical regression across the data set to attempt to show what round a player would get drafted in. The first data set was broken into Offense (2910 players) and Defense (2726 players) categories to start to normalize the information. Using only the combine tests from the years 2000 to 2017 (Height, Weight, 40 yard dash, Vertical Jump, Bench Press Reps, Broad Jump, 3Cone Shuttle) to determine the round a player would be drafted resulted:
Offense
Training Data Score: 0.3913840513290559
Testing Data Score: 0.39697802197802196
Defense
- Training Data Score: 0.320450097847358
- Testing Data Score: 0.3196480938416422
The dataset was then condensed to a position level (OT 437 players) to see if a smaller subset of the data would produce stronger results. The combine tests (Height, Weight, Bench Press Reps, Broad Jump, 3Cone Shuttle) were also more focused to the position. Unfortunately, the results were again similar:
- Training Data Score: 0.327217125382263
- Testing Data Score: 0.33636363636363636
The data was then expanded to include college statistical production. We narrowed the set to the Quarterback (QB 195 players) position from the years 2006 to 2016. The datasets were merged by combine results and quarterback production ("Height", "Wt", "40YD", "Vertical", "Broad Jump", "3Cone", "Shuttle", "Pass Att", "Pass Comp", "Pass Yard", "Pass Int", "Pass TD", "Rush Att", "Rush Yard", "Rush TD").
- Training Data Score: 0.5068493150684932
- Testing Data Score: 0.32653061224489793
The results from the testing data concluded that combine results and previous college production will not be enough to predict what round a player will get drafted. There needs to be further qualitative analysis done for each player.
NFL Statistics
After initially fitting and testing combine and college statistics for football players, we wanted to take our next step in reverse. Our goal was to use NFL career data, to determine what round of the NFL draft our players should have been drafted in. We previously ran tests to see why NFL general managers determined who to draft in certain rounds, and for this step we wanted to see how often these GMs made the correct choice. To do this, we took NFL statistics for every drafted player from 2000 to 2017. Being a Kaggle dataset, we uploaded our csv in a pandas data frame, and then merged with our previous dataset of NFL players. Now, we have college, combine, and NFL statistics for all players from 2000-2017. For our NFL draft predictions, we wanted to take a different classification route, and run a Random Forest Classification. In order to do this, we uploaded our newly created CSVs, and created two new pandas data frames. After cleaning our data, we dropped our label from one of our data frames, and fitted our train and testing values. We imported our random forest classifier, and fit our model with our desired trained labels. Our first process was to acquire a mean absolute error and an accuracy percentage for our prediction.

Now with our fitted and running classifier, we wanted to determine which of our trained and tested values sklearn used to calculate our accuracy. We listed our importances and wrote our tree to a PNG file.


Our random forest classifier displayed a list of predictions, which is the round our players should have been drafted in based on their statistics. In order to better visualize our data, we called our original data frame, and merged them to display our final prediction data frame. Our final product is our prediction data frame, which displays a player’s name, the round they were actually drafted in, and then finally the round their NFL statistics determine their drafted round should have been.

Conclusions
From analyzing the combine data alone, our model had a prediction success rate of approx. 65% which would indicate that while the combine performance of each player is very important, it is not by any means the full set of data that is looked at when determining whether a player will be drafted or not. This obviously makes complete sense, as college performance stats are readily available and coaches heavily lean on these when assessing players. An example would be Jarvis Jenkins in the 2011 draft. He did not score in the top 50 of any metric but was still a 2nd round pick This would lead us to predict that when adding college performance data to our model the accuracy would increase significantly, however this only took our model to 71% accuracy.
The main aim of this project was to analyze performance stats to see if we could predict at what round in the NFL draft a player would be picked. Given the amount of data we had, we were aiming of an accuracy of 65 to 70%. Our model only gave us an accuracy of 32%. While this does seem very low, it is interesting to note that when we ran a model to calculate predicted draft round pick vs actual pro performance the accuracy was only 52%. This tells us that professional scouts struggle to predict pro performance based on college performance. What this tells us is that football may be not as stats driven as we thought. The unpredictable nature of the game is what makes it so enjoyable and if we did have a 100% accurate model this would probably no longer be the case.